
How to Improve the Reasoning Ability of LLMs with Chain of Thoughts
Chain of thoughts is a way of thinking about or understanding something by following a series of connected ideas. It can be used to solve problems, make decisions, or simply to learn more about the world around us.


Imagine you are a large language model (LLM) that is tasked with answering the question "How many eggs does Joe have?" Joe has 20 eggs to start with. He buys 2 more cartons of eggs, each of which contains 12 eggs. How many eggs does Joe have now?
If you are a traditional LLM, you might struggle to answer this question. You would need to understand the meaning of the words "Joe", "eggs", "cartons", and "buys". You would also need to know how to perform arithmetic operations. And finally, you would need to be able to reason about the problem and follow the chain of logic from start to finish.
This is where the chain of thought prompting comes in. Chain of thought prompting is a technique that helps LLMs to reason by breaking down complex problems into smaller, easier-to-solve steps. In the case of the egg problem, the chain of thought might look like this:
—-> Joe has 20 eggs.
--> He buys 2 more cartons of eggs.
--> Each carton contains 12 eggs.
Therefore, he now has 20 + 2 * 12 = 36 eggs.
By breaking down the problem into smaller steps, the LLM is able to reason about it more easily and arrive at the correct answer.
Types of chain of thought prompting:
There are two main types of chain of thought prompting:
Zero-shot prompting:
It involves adding "Let's think step by step" to the original prompt. Let's try a simple problem and see how the model performs:
Prompt:
I went to the market and bought 10 apples.
I gave 2 apples to the neighbor and 2 to the repairman.
I then went and bought 5 more apples and ate 1.
How many apples did I remain with?Output:
11 applesThe answer is incorrect! Now Let's try with the special prompt.
Prompt:
I went to the market and bought 10 apples.
I gave 2 apples to the neighbor and 2 to the repairman.
I then went and bought 5 more apples and ate 1.
How many apples did I remain with?
Let's think step by step.Output:
First, you started with 10 apples.
You gave away 2 apples to the neighbor and 2 to the repairman, so you had 6 apples left.
Then you bought 5 more apples, so now you had 11 apples.
Finally, you ate 1 apple, so you would remain with 10 apples.It's impressive that this simple prompt is effective at this task. This is particularly useful where you don't have too many examples to use in the prompt.
Few-shot prompting:
This involves providing the LLM with a few examples of how to solve a particular type of problem. For example, you could provide the LLM with three examples of how to solve an arithmetic problem. The LLM would then learn from these examples and be able to solve similar problems on its own.
Let's try to add some examples to see if few-shot prompting improves the results.
Prompt:
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: The answer is False.
The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.
A: The answer is True.
The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.
A: The answer is True.
The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.
A: The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A: Output:
The answer is False.This is how your LLM can learn more by giving it more sample examples.
Automatic chain of thought prompting:
This involves automatically generating a chain of thought prompts for a given problem. This can be done by using a technique called reinforcement learning. In reinforcement learning, the LLM is given a reward for solving a problem correctly. The LLM can then use this reward to learn how to generate a better chain of thought prompts.
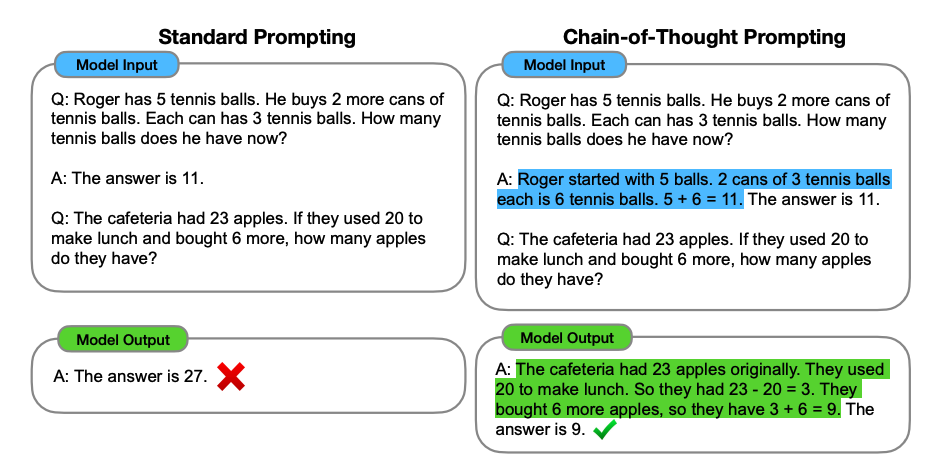
Below is an example of all 3 techniques with comparison.

Why do we need it?
Chain of thought prompting is a powerful technique that can be used to improve the reasoning ability of LLMs. It can be used to solve a variety of problems, including arithmetic, commonsense reasoning, and natural language inference.
Consider the example where a normal prompt gives the wrong result but minor tweaking in question gives us the better correct output. It's like exploring hidden skills of LLM.
Comparison with other available solutions
There are several other techniques that can be used to improve the reasoning ability of LLMs. These include:
- Neural-symbolic reasoning: This technique combines the strengths of neural networks and symbolic reasoning to solve problems.
- Reinforcement learning: This technique allows the LLM to learn how to solve problems by trial and error.
- Meta-learning: This technique allows the LLM to learn how to learn new tasks.
Chain of thoughts is a relatively simple technique, but it can be effective for a variety of problems. It is a good choice for problems that can be decomposed into a series of smaller, simpler steps.
Conclusion
Chain of thoughts is a powerful technique that can be used to improve the reasoning ability of LLMs. It is a simple and effective way to break down complex problems into smaller, simpler steps. This makes it easier for the LLM to reason about the problem and find a solution.
I hope this article has given you a good understanding of VAE. If you enjoyed the article do consider checking more.


